A Quick Guide To Regular Expressions

Jul, 25th 2023
Regular expressions are present in almost all programming languages (Python, PHP, Javascript…), as well as in Linux commands (grep, sed…) and in many other high-level languages and applications.
So, why are they so widely present? what exactly are they used for? and how can we start using them ourselves?
Before we go ahead and address these questions, I am going to start first by addressing the elephant in the room and answer the first question that should be pondering in your mind.
What are Regular Expressions?
A regular expression (or Regex) is a string of characters that specifies a search pattern. It is often used to match text while performing “find” and/or “replace” operations.
I know this definition might be confusing, which makes regular expressions quite difficult to understand at first. But don’t worry, you’ll soon grasp their utility as we progress through this article, in which we are going to learn how to read and write regexes, starting from simple and short examples to more advanced patterns.
Why use Regular Expresions?
You might have used wildcards before in your search queries. For instance, when searching for *.html, you can retrieve all files that end with .html.
Well, regular expressions work in a similar way, except that they are more powerful and allow for more advanced text filtering options.
When it comes to learning new concepts, examples are a lot more effective than mere definitions. So, here you go. These couple of examples should help you better understand why we use regular expressions.
- Example 1 : To validate email addresses
\b[a-zA-Z0-9_.+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}\b
- Example 2 : To validate phone numbers
^\+?([0-9]{1,3})?\s?\(?[0-9]{3}\)?[-\s.]?[0-9]{3}[-\s.]?[0-9]{4,6}$
- Example 3 : To validate IP addresses
\b[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\b
I can already see the confusion in your eyes. But hey, rest assured, this isn’t Chinese. In fact, I dare you that by the end of this article, you will be able to read and understand what these expressions mean.
As you can see, by using the above examples, we can check if a certain string is an email address, a phone number, or an IP address. And these are not the only things that you can validate. Once you learn how to write regular expressions, you will be able to check for literally any type of string.
If you want to verify on your own the above examples, or the regex patterns that we will see in the rest of this article (Which I encourage you to do), then you can do that on Regex101. This is a useful website that offers an interactive regex debugger, where you can test your own regex patterns against an input string.
How to Write Regular Expressions?
Now that you have witnessed with your own eyes what Regular Expressions are capable of, it is time for you to start learning the art of Regex-Fu.
So, without any more delay, your training begins now.
Literal Characters
The most basic regular expression you can write is simply using the literal text string that you wish to find.
For instance, using discovery as the regex pattern against the string : I made a discovery today will match the colored occurrence of the word discovery.
The word discovery occurs one time only in this example. If there had been more than one occurrence of that word, then, depending on the options that you’re using regex with, it may only match the first occurrence of the literal string.
The way you define these options (Sometimes also called flags) varies depending on the application or programming language you’re using, as not all implementations of Regex are equal. If you’re only using Regex101 to test your patterns, then you can click on the ‘mg’ characters as shown in the image below to set your Regex options.
The most important flags that you may want to set are global (To return all occurrences instead of only the first one) and insensitive (To perform case insensitive matches. That is, without differentiating between uppercase and lowercase letters).
Enough with flags now, let’s go back to our regex patterns.
Character Classes
A character class is used to match one of many given characters. To specify one, you should enclose the characters into square brackets [].
For instance, using the expression [gst]old will match with the words gold, sold, as well as told. However, it won’t match with gstold.
You can also use a hyphen in a character class to specify a range. For instance, [a-z] will match all characters between a and z (That is, all lowercase letters). You can also match only digit numbers by using [0-9].
To make things even more interesting, you can combine all these ranges in a single character class : [a-zA-Z0-9._-]. This class will match with all lowercase and uppercase letters, digit numbers, as well as the dot ., underscore _, and hyphen - characters.
If you find it tiring to have to type all these ranges, then you can use shorthand classes for the ones that people use often. You can use \d instead of [0-9] to match a digit number, or \w instead of [a-zA-Z0-9_] to match a word character (all letters, digits, plus the underscore character).
Now, as much as these classes are powerful and flexible in matching all sorts of characters, they are still limited in that they only match one character at a time. On their own, classes won’t be able to match an entire word. This is where quantifiers come into play.
Quantifiers
A quantifier specifies how many consecutive occurrences of a specific character, or a class has to be present in a string before it can match it.
There are three main special characters that you can use as quantifiers, and these are :
- The star character
*provides a match if zero or more consecutive occurrences of the previous element are present. - The plus sign
+matches if one or more consecutive occurences of the previous element are present. - And the question mark
?matches if zero or one occurrence of the previous element is present.
Here are some examples to make things clearer:
No+will match with ‘No’, ‘Noo’, ‘Nooo’, ‘Noooo’… (You can see where I’m going, I don’t need to continue forever).computers?will match with ‘computer’ and ‘computers’ (Zero or one occurrence of the character ‘s’).0*[0-9]?will match with any number between 0 and 9, whether it is written as a single digit (0,1,…,9), or starting with one or more zeros (ex. 01, 0005, 003).
You can also specify the exact number of times that you want the previous element to match by using curly braces {}.
As always, a couple of examples will demonstrate the three main ways you can use curly braces as quantifiers :
[0-9]{5}will match any number with 5 digits.a{1,3}ndwill match withand,aand, as well asaaand(That is, with any number of occurrences between 1 and 3).- And
[a-zA-Z0-9]{8,}will match with any string of 8 or more characters (This can be used to validate passwords when requiring users to choose passwords with at least 8 characters of length).
Groups
You can use parentheses around a set of characters to create a group. If you add a quantifier after it, then it would apply to the entire group, not just the last character, or class.
As an example, (ha){2,} will match with haha, hahaha,… (Any time there is a laugh).
You can also use a group with an alternation. This is the equivalent of the or operator.
For example, I love (coffee|tea) will match with both I love coffee, and I love tea.
You can also use parenthesis to create a capturing group. Every time you use parenthesis in your expression, a capturing group is created. You can think of it as a variable that will hold the text string that is matching between parenthesis.
To go back to our previous example : I love (coffee|tea), we have one set of parenthesis, which means we only have one group (group 1). If we run this regex pattern against the string : I love tea, then group 1 will contain the string tea.
Retrieving the value contained in capturing groups depends on the programming language or application that you’re using regex with. However, if you are only testing with Regex101, then you can still see their content in the “Match information block” on the right side as shown in the screen below:
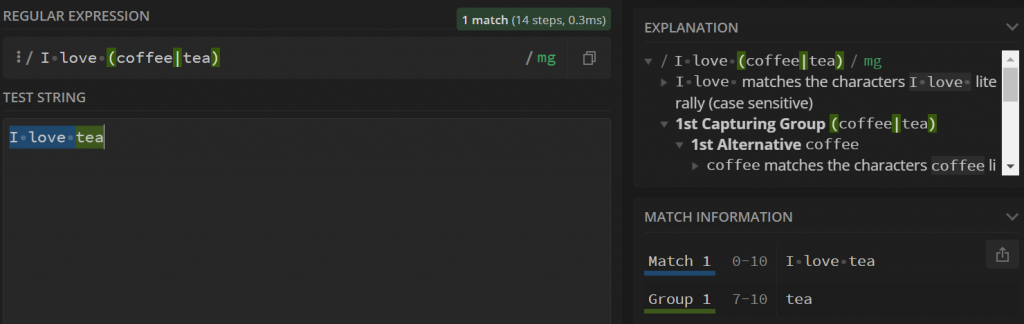
This example has only one capturing group, but you can have as many as you want.
The Dot
The Dot . in regex has a special meaning. It matches all characters (Except for a line break).
The regex pattern c.ffee will match with coffee, caffee, c8ffee, c-ffee…
It is used often in combination with quantifiers (+, *,…).
The regex pattern .* will match any string that is given as its input. On its own, it doesn’t serve for anything. However, when combined with other regex elements, it can be used to fill in any part of a pattern where we don’t know what the string that would match it will contain.
For example, the regex pattern c.*s, will literally match anything that is delimited by c and s.
Anchors
Anchors allow you to match depending on the position in the string.
The most used anchors are : ^ to match the beginning of the string (or a line, if the input string is multi-line), and $ for the end of the string (or line).
The regex pattern ^C will match any string (or line) that starts with the letter C. It would match with the string : Computer Stuffs, but not with Doing Computer Stuffs. This is because the latter starts with the character D, and not C.
Similarly, s$ will match any string (or line) that ends with the letter s. It would match the input string : Computers, but not Computer.
Another useful anchor is : \b, which is used to specify a word boundary. So, if you use the regex pattern \bcomputer\b, then this would match the string : I own a computer, but not I own computers. This is because, in the latter, there is an s character after the string computer, and not a word boundary.
Escaping metacharacters
As we’ve seen in the previous sections, many characters have special meanings when used in a regex string. These are : .+?*[](){}....
Now, what if we want to match literally one of these characters in a string input?
For instance, what if we want to match a phone number starting with the character +. If we use the regex string +[0-9]{15}, then this would generate an error. This is because we are using the + sign without a preceding element to which the quantifier would apply.
To bypass this, and force the interpretation of these metacharacters as literal characters, we can use \ before them. So, in our example, the proper string to use would be \+[0-9]{15}.
Note that the above regex pattern is oversimplified. It won’t be able to match phone numbers that contain hyphens within them. For the sake of this example, it was simplified to only match with phone numbers starting with +, followed by 15 digit numbers. If you want a more accurate regex for phone number validation, you can take a look at the one provided as an example earlier in this article.
Conclusion
We have reached the end of this article, you should now be able to write your own regex patterns that suit your needs. I invite you to go back to the examples provided at the beginning of this article to try and understand why they work
If you want to challenge yourself even further, you can also try to write regular expressions for validating dates, credit card numbers, and checking password complexity. These should keep you busy for a while.
Comments
No comments